
视频教程请前往微信公众号查看
直达链接:https://mp.weixin.qq.com/s/YmUgo-FiynajXvHeePPyFQ?token=856548824&lang=zh_CN
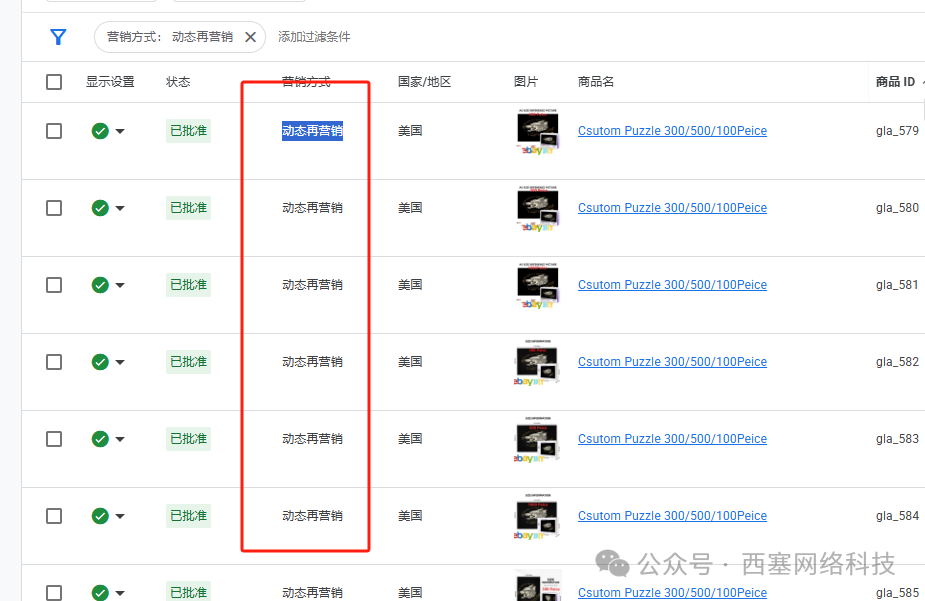
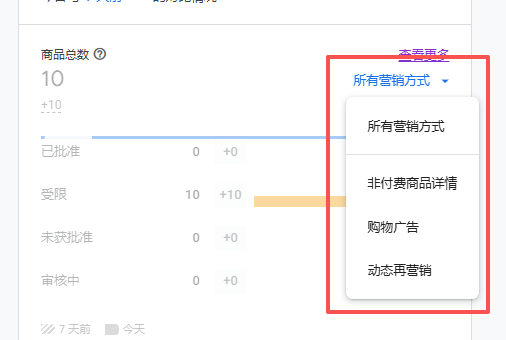
这料猛不猛,一审100%通过
视频刚刚录完就绿了,真真的
不信看图片:
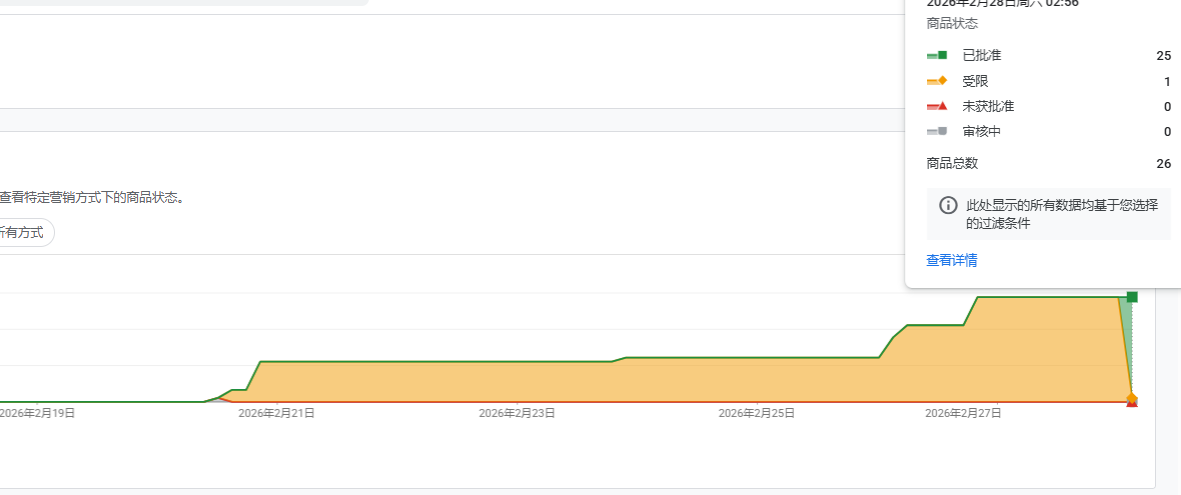
关注我们微信公众号:

视频教程请前往微信公众号查看
直达链接:https://mp.weixin.qq.com/s/YmUgo-FiynajXvHeePPyFQ?token=856548824&lang=zh_CN
这料猛不猛,一审100%通过
视频刚刚录完就绿了,真真的
不信看图片:
关注我们微信公众号:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。

评论留言